웹 서비스 요청의 80%는 단순 읽기 작업이라고 한다. 따라서 개발 속도는 빠르지만, 상대적으로 성능이 떨어지는 Python 기반의 웹 서버를(Flask, Django 등) Gateway로 두고 Core Engine으로 고성능 서버(Go 등)를 활용하는 MSA 방식이 요즘 유행이다.
Python 기반의 웹 서버는, GIL 제약에 의해 멀티스레드 병렬 처리를 활용하지 못 하지만 I/O 작업에서는 전혀 문제가 없다. I/O 대기시간엔 CPU를 사용하지 않는 데다가, 기다리는 동안 GIL을 놓고 추가 스레드를 생성해 다른 작업을 맡길 수 있기 때문이다. 명시적 비동기 처리를 하지 않더라고 비동기 "처럼" 동작하기 때문에 I/O 작업엔 크게 무리가 없고(그렇다고 더 빠르단 건 아니다), 개발 속도가 빠르다는 장점이 합쳐져 이러한 MSA 방식이 트렌드가 된 것 같다.
오늘은 이러한 Gateway 대상 요청의 약 80%를 차지하는 DB 읽기 작업에 대한 병목을, 캐싱을 적용해 해결해 볼 것이다. 캐싱은 인메모리 DB인 Redis를 활용해 구현할 것이고, Go 서버는 그냥 두고 Gateway인 Flask 서버에서만 작업할 것이다. 데이터는 Faker 라이브러리를 활용해 100만 건을 넣을 것이고, 인덱스를 누락시켜 100만 건 데이터를 Full Scan 하게 만들어 조회 성능을 고의적으로 조금 떨궈둘 것이다.
측정 데이터는 다음과 같다.
InfluxDB: P95 Latency (응답시간), Throughput (처리량), Drop rate (총 요청 대비 드랍률)
Node Exporter, Prometheus: 호스트 메모리 사용량
Prometheus Counter: 캐시 히트율
비교 대상은 다음과 같다.
A. 매 요청마다 캐싱 없이 데이터 직접 조회 후 응답
B. 캐싱 활용, 캐시 없을 경우 직접 조회, 있을 경우 캐시 응답
더미 데이터 삽입

Faker 라이브러리를 활용해 PostgreSQL에 더미 데이터 100만 건을 삽입했다.
캐시 히트율을 높이기 위해 100개의 이메일을 미리 만들고, 100만 건 중 80%(80만건)는 100개 중 한개의 이메일을 사용하도록 구성했다. 만들어진 100개의 이메일은 JSON 파일로 따로 저장해 두고, K6로 트래픽을 발생시킬 때 활용할 것이다.
조회 쿼리
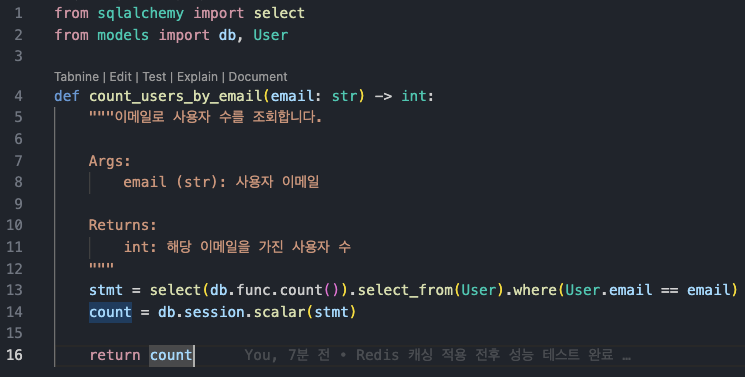
테스트에서 조회를 담당해 줄 쿼리이다.
내용은 아주 간단하다. 입력받은 email과 같은 email을 가진 사용자의 수를 리턴하는 것이다.
쿼리는 간단하지만, 총 데이터가 100만 건이기 때문에 조회 요청이 올 때마다 100만 건을 Full Scan 해야 하고, 일치하는 이메일을 찾았더라도 해당 이메일을 가진 총 사용자 수를 세야 하기 때문에 항상 일정하게 느리게 동작한다.
캐시를 활용하지 않는 요청은 항상 이 함수를 호출할 것이며,
캐시를 활용하는 요청은 캐시가 없을 때만 제한적으로 호출할 것이다.
캐싱 구현
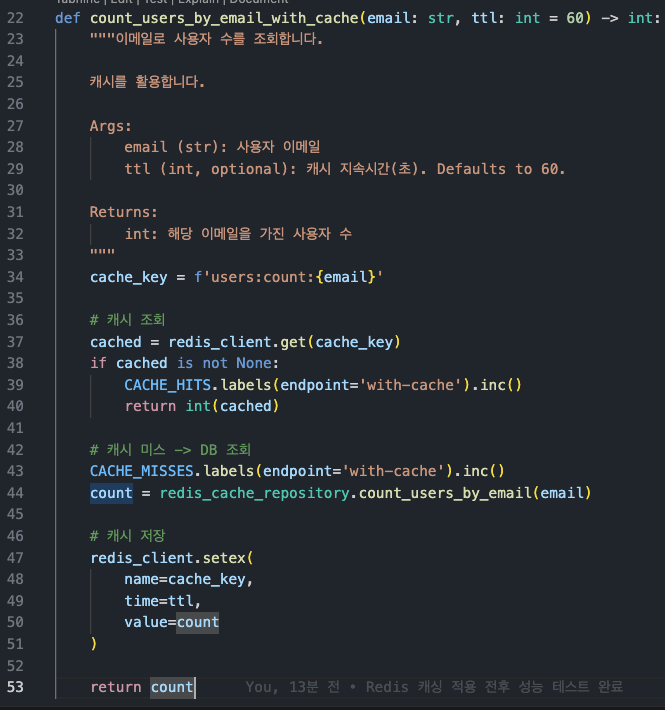
조회 요청이 들어왔을 때 함수는 아래와 같이 동작한다.
캐시가 존재할 경우: 즉시 캐시 리턴
캐시가 존재하지 않을 경우: DB조회 후 캐시 등록하고 값 리턴
CACHE_HITS, CACHE_MISSES 상수는, 캐시 히트율을 계산하기 위해 Prometheus에서 정의한 Counter 객체이다.
테스트 조건
RPS(초당 요청 수): 30 -> 50 -> 75 -> 100 -> 150 -> 300
DURATION(요청 지속시간): 30 고정
테스트 대상: P95 Latency, Throughput, Drop rate, Memory Usage, Cache Hit rate
RPS를 30에서 300까지 올리며, no-cache/with-cache 연산을 번갈아가며 진행할 것이다. with-cache 테스트 후에는 항상 캐시를 삭제한 후 진행한다.
테스트 결과 - P95 Latency

| 구분 | 30 RPS | 50 RPS | 75 RPS | 100 RPS | 150 RPS | 300 RPS |
| 캐싱 X | 135ms | 3.277s | 9.34s | 10.75s | 13.725s | 14.375s |
| 캐싱 O | 21.8ms | 12.2ms | 11.9ms | 33.3ms | 53.9ms | 307ms |
30RPS부터 약 6배 정도의 차이로 시작했다가, 50RPS로 한단계 뛰자 마자 수백 배 이상으로 격차가 벌어졌다.
가장 차이가 많이 나는 구간은 75RPS인데, 약 785배 차이가 난다!!!
하지만 난 RPS가 늘어날 수록 기하급수적으로 차이가 벌어질 것이라 생각했는데, 100 RPS부터는 격차가 점점 줄어들고 있다. 왜 그런지 생각을 해 보았다.
그 이유는 매 테스트가 끝날 때마다 캐시를 새로 쌓아야 하기 때문이었다. 캐시가 저장된 상태로 즉시 테스트를 이어가는 게 아닌, 매번 새롭게 캐시를 쌓아야 하기 때문에 캐시를 쌓는 과정에서의 오버헤드가 결과값에 영향을 주는 것이었다.
그래서, 일단 이대로 진행하고 글 마지막에서 캐시를 지우지 않고 최대한 활용하여, 캐싱의 성능 한계를 측정해 보겠다.
테스트 결과 - Throughput

| 구분 | 30 RPS | 50 RPS | 75 RPS | 100 RPS | 150 RPS | 300 RPS |
| 캐싱 X | 30개 | 42개 | 40개 | 42개 | 38개 | 40개 |
| 캐싱 O | 30개 | 50개 | 75개 | 100개 | 150개 | 300개 |
초당 처리량은 30RPS일 땐 둘 다 동일했다가, 50RPS부터는 캐싱 X의 경우 40개 초반 선에서 쭉 정체되었다.
반면 캐싱 O의 경우 RPS와 처리량이 똑같이 상승하며 매우 안정적인 모습을 보이고 있다.
테스트 결과 - Drop rate

| 구분 | 30 RPS | 50 RPS | 75 RPS | 100 RPS | 150 RPS | 300 RPS |
| 캐싱 X | 0% | 7.71% | 24.5% | 43.2% | 66.2% | 81.3% |
| 캐싱 O | 0% | 0% | 0% | 0% | 0% | 1.1% |
드랍률에선 조금 더 의미있는 차이를 보이는 것 같다.
30 RPS 에서는 둘 다 0%를 기록하며 큰 문제가 없었지만, 캐싱 X의 경우 50 RPS부터 7%의 드랍률을 보이기 시작하더니 75 RPS 부터는 사용하지 못 할 수준으로 드랍률이 상승해 버렸다.
반면 캐싱 O의 경우 300RPS에서도 드랍률 1.1%를 유지하며 꽤 안정적인 성능을 보였다. (약 80배 차이!!)
그러나 저 1.1%라는 수치도, 초반에 캐시를 수집하는 과정에서 생긴 드랍일 확률이 높다.
테스트 결과 - Memory Usage & Cache Hit Rate

그래프만 보면 아마 이해하기 어려울 것 같다.
내 테스트는 15:55 ~ 16:03(약 8분)동안 진행되었다. 현재 대시보드는 15:30 ~ 16:25 까지의 메모리 사용량을 담고 있다. 그래프를 보면 35 ~ 43 정도 사이에서 메모리가 계속 왔다 갔다 하는데, 고부하 테스트를 진행한 시간대에도 최대 43~44 정도의 수치밖에 보이지 않았다. 평소 사용량이 30 후반 정도인 걸 감안하면, Redis를 도입하고 감수해야 하는 메모리 측면에서의 손해가, 별로 크지 않다는 사실을 알 수 있다.
이제 Cache Hit Rate를 계산해 보자. 전체 테스트의 평균을 구할 것이다.
캐시 히트 수: 85327
캐시 미스 수: 3808
캐시 히트율: 85327 / (85327 + 3808) -> 95.73%
95.73%는 아주 높은 수치에 속하며, 실무에서도 70%이상의 히트율이 나오면 충분하다고 판단한다. 아무래도 히트율을 좀 높게 잡았다 보니 성능 차이가 더 극명하게 갈렸지만, 캐싱 구현의 복잡성과 도입 리스크에 비해, 극적인 성능 개선이 일어난다는 사실 만큼은 충분히 증명되었을 것이라 생각한다.
테스트 결과 - 미리 캐싱 후 한계 측정 (P95 Latency, Drop rate)
| 구분 | 300 RPS | 500 RPS | 1000 RPS |
| P95 Latency | 4.15ms | 7.33ms | 1.22s |
| Drop rate | 0% | 1.6% | 12.64% |
미리 캐싱하지 않았던 아까 실험에서는, 300RPS 기준 Latency 307ms Drop rate 1.1% 였다.
그러나 미리 캐싱을 해 두니, 500RPS에서도 이전 300RPS보다 훨씬 빠른 성능을 보였다.
1000RPS에서는 병목이 시작되었는지 1.22s, 12.64%라는 결과가 나왔는데, 이마저도 캐싱X 의 50RPS와 비슷한 수준이다. 즉, 엄청나게 차이가 난다.
왜 이렇게 빠를까?
원리는 아주 간단하다. 우선 캐시는 Redis에 key-value 형태(Hash Table 기반)로 저장되기 때문에, 캐시 데이터가 10개든 10억 개든 항상 상수 시간 O(1)에 조회가 가능하다. 심지어 Redis는 메모리 기반 데이터베이스이기 때문에, 일반적인 디스크 기반 DB (MySQL, PostgreSQL 등)보다 압도적으로 빠르다. 심지어 DB 조회를 생략하기 때문에 DB 부하가 줄고, 애플리케이션 서버에서 I/O 대기시간도 사라지기 때문에 리소스 절약 효과도 크다.
-> DB 조회 결과를 매우 빠른 저장소인 Redis에 미리 저장해 두고, 반복적인 조회 요청이 들어올 때 실제 DB 조회를 생략하고 즉시 Redis에서 데이터를 꺼내 응답하기 때문에 매우 빠른 것이다.

참고로 캐싱 적용 전/후 단일 요청 응답시간은 이런 차이가 난다. (데이터 100만 건 기준)
캐싱 적용 전: 109.985ms
캐싱 적용 후: 2.156ms (약 51배 차이!!!)
==========
msa-perf-lab 깃허브:
https://github.com/YangSunkue/msa-perf-lab
==========