[msa-perf-lab] CPU Bound 작업 성능 비교: Flask 자체 연산 vs Go 위임 - 멀티스레드 병렬 처리의 효율성 증명
저번 시간엔 RabbitMQ 비동기 처리를 통해, Flask의 I/O Bound 병목점을 해결해 보았다. 응답시간은 약 500배 차이가 났었고, 처리량 및 드랍률도 RPS가 증가할수록 격차가 심해졌다.
이번 시간엔 Flask의 나머지 대표적 병목인 CPU Bound 작업을 Go에 위임해 볼 것이다. Flask는 Python의 GIL 한계 때문에 멀티코어 + 병렬 처리의 이점을 전혀 얻을 수 없어, CPU 연산 중엔 GIL을 놓지 못해 완전히 블로킹 되어 성능이 급감한다. 이러한 CPU Bound 작업을 병렬 처리에 특화된 Go에 위임하여, 어느 정도의 성능 향상을 가져오는지를 테스트 할 것이다.
기존 방식인 Flask 자체 연산 방식은, CPU 연산을 수행하는 동안 GIL에 묶여 동시에 단 하나의 코어(스레드)만이 활동 하게 된다. 만약 연산에 10초가 소모된다고 가정하면, Flask 서버는 이 연산을 수행하는 동안 다른 그 어떤 작업도 할 수 없다. 즉 엄청난 병목을 초래한다.
개선 방식인 Go 위임 방식은, GIL 제한이 없고 멀티스레드 + 멀티코어 + 병렬 처리 + Goroutine의 엄청난 효율성을 전부 활용할 수 있기에 병목 개선 및 극적인 성능 개선이 일어날 것으로 생각된다. 정말로 그럴지 테스트 해 보자.
이전 성능 테스트에서는 K6 + InfluxDB를 활용해 Latency, 처리량, 드랍률을 계산했지만, 이번엔 CPU 사용률도 측정해야 하기 때문에 Node Exporter + Prometheus 조합을 추가해 CPU 사용률을 측정했다.
비교 대상은 아래와 같다.
A. Flask 서버에서 직접 CPU 집약적 연산 후 응답
B. Flask 서버가 Go 서버에게 CPU 집약적 연산 위임 후 결과를 받아 응답 (gRPC 통신)
prometheus 설정

원래는 cAdvisor를 사용해 Flask/Go 컨테이너별 CPU 사용률을 측정하려고 했으나, 이번엔 Node exporter를 활용하기로 했다.
1초마다 Node exporter로 CPU, 메모리 등 호스트 데이터를 수집해, 프로메테우스에 저장한다.
Latency, Throughput, Drop-rate는 이전 실험에서 그랬듯 K6 + InfluxDB 조합 그대로 측정할 것이다.
CPU 집약적 연산 함수

이번 실험의 메인이 될, 연산 함수이다. Go 서버 측 연산 함수도 동일하게 구현되어 있다.
기본적으로 10만 번 반복하며, 입력받은 level에 따라 연산 횟수를 증가시킨다.
예를 들어,
Level 1 -> 10만번 연산
Level 10 -> 100만번 연산
Level 1000 -> 1억번 연산
이런 흐름이다.
테스트 조건
RPS(초당 요청 수): 50 고정
DURATION(요청 지속시간): 30 고정
COMPLEXITY_LEVEL(연산 난이도): 1 -> 3 -> 5 -> 10 -> 25
테스트 대상: P95 Latency, Throughput, Drop-rate, CPU-Usage
연산 난이도를 1에서 25까지 올리며, Flask/Go 연산을 번갈아가며 진행할 것이다.
테스트 결과 - P95 Latency
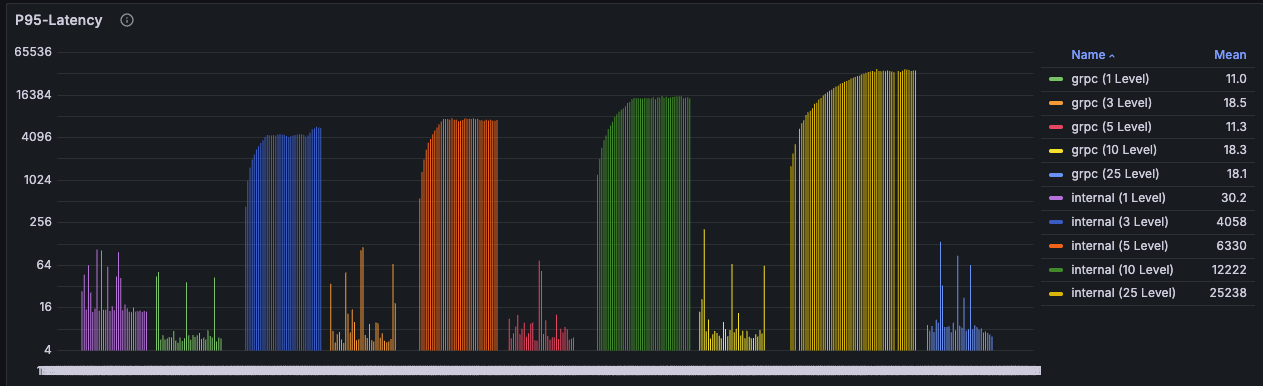
| 구분 | Level 1 | Level 3 | Level 5 | Level 10 | Level 25 |
| Flask | 30.2ms | 4.058s | 6.33s | 12.222s | 25.238s |
| Go 위임 | 11ms | 18.5ms | 11.3ms | 18.3ms | 18.1ms |
처음부터 엄청난 결과다.
Level 25(연산량 250만회) 기준 Flask는 25초, Go는 18.1ms로 무려 1394배 차이가 난다!!
Flask는 Level 1에서 30.2ms로 나쁘지 않은 속도를 보였지만, Level 3 이후부터는 Second 단위로 100배 이상 급증했다.
반면 Go는 Level 1부터 Level 25까지 거의 비슷한 응답속도를 보였다. 이 정도 레벨에서는 끄떡도 없는 듯 하다.
테스트 결과 - Throughput (초당 처리량)
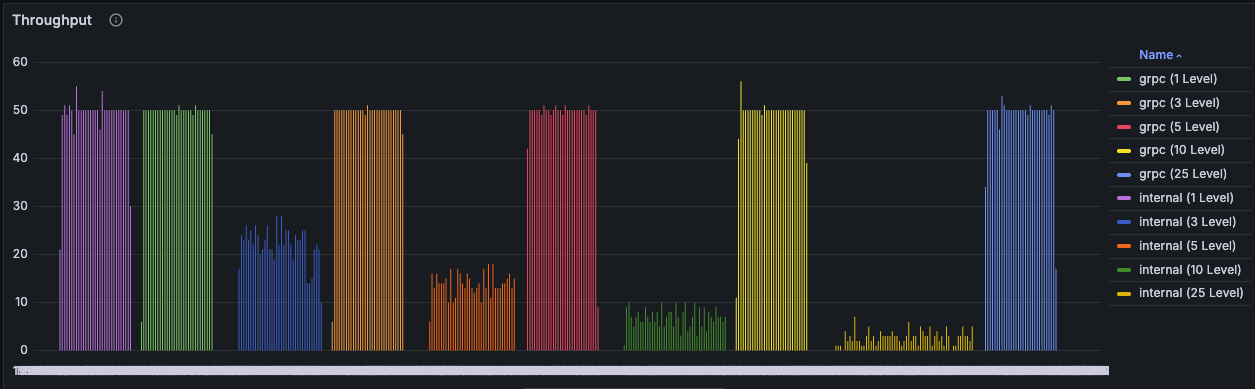
| 구분 | Level 1 | Level 3 | Level 5 | Level 10 | Level 25 |
| Flask | 50개 | 22개 | 14개 | 8개 | 3개 |
| Go 위임 | 50개 | 50개 | 50개 | 50개 | 50개 |
초당 처리량도 엄청난 차이를 보인다.
Level 25 기준 Flask는 3개, Go는 50개로 약 17배 차이가 나며, Go가 매우 안정적인 것으로 보아 Level을 아주 많이 올려도 50개의 Throughput을 유지할 것으로 예상된다.
Flask는 Level 1에서는 50개의 요청을 전부 처리했지만, Level 3부터는 절반 이하로 떨어지더니 Level 25가 되자 못 써먹을 정도로 곤두박질 쳤다.
반면 Go는 레벨에 관계없이 안정적으로 50개의 요청을 전부 처리해 내는 모습이다.
테스트 결과 - Drop-rate (총 요청 수 대비 드랍률)

| 구분 | Level 1 | Level 3 | Level 5 | Level 10 | Level 25 |
| Flask | 0% | 47.4% | 65.8% | 79.9% | 89.2% |
| Go 위임 | 0% | 0% | 0% | 0% | 0% |
이 드랍률이야말로 Go의 안정성을 가장 잘 보여주는 지표가 아닐까 싶다.
Flask는 Level 1 에서는 안정적이었지만, Level 3에서는 절반, 그 이후론 대부분의 요청을 드랍하며 GIL이 가진 병렬 처리 제한의 한계를 명백히 보여주었다. 사용할 수 없을 수준이다.
Go는 Level 25 정도는 전혀 무리가 아니라는 듯이 당당히 드랍률 0%를 기록했다.
테스트 결과 - CPU-Usage

| 구분 | Level 1 | Level 3 | Level 5 | Level 10 | Level 25 |
| Flask | 12% | 17% | 16% | 16% | 16% |
| Go 위임 | 9% | 11% | 10% | 9% | 10% |
이 지표는 약간 설명이 필요할 듯 하다.
내 Flask는 현재 단일 프로세스(워커)로 가동중이기 때문에, GIL 제약에 의해 동시 활동 가능 스레드는 1개이므로 단 1개의 CPU 코어만 활용한다. 내 PC의 총 코어 수는 8개인데, 그 중에 1개만 쓸 수 있으니 이론적으로 Flask의 CPU 사용률 한계는 12.5%이다.
하지만 12.5%를 초과하는 이유는, Node exporter는 호스트의 CPU 사용률을 측정하기 때문에 Flask + 브라우저 및 기타 프로그램의 CPU 사용률이 함께 집계되기 때문이다.
자, 이제 결과를 보자.
Flask는 Level 1 에서 12%로 CPU를 전부 활용하지 않았지만, Level 3부터 활용 가능한 CPU를 최대로 활용하며 고군분투 하고 있다.
Go는 Level 1 부터 Level 25 까지 일정한 CPU 사용률을 보인다. GO는 GIL 제약이 없기 때문에 8개 코어를 모두 활용할 수 있는데, 전부 활용하게 되면 CPU 사용률이 100%로 찍힌다. 그 말은, 이 정도의 연산은 GO에게 CPU를 더 쓸 필요도 없는 가벼운 연산이라는 뜻이 되겠다.
이제 Go가 Flask보다 CPU 집약적 연산에 훨씬 강하다는 것은 증명되었다. 그러나, 이쯤 되면 Go의 한계는 어디인지가 궁금해진다. 바로 테스트 해 보자.
테스트 결과 - CPU-Usage (Go의 한계 측정)

| 구분 | Level 500 | Level 600 | Level 700 | Level 800 | Level 1000 |
| Go 위임 | 58% | 62% | 100% | 100% | 100% |
레벨이 확 뛴게 약간 웃길 정도다. 레벨을 조금씩 올리며 병목지점을 찾으려 했는데, 너무 잘 버티는 바람에 한번에 Level 1000으로 올리면서 병목지점을 찾았다.
Level 500, 600도 Go에게 크게 무리한 작업은 아니었다. Level 600 기준 드랍률은 거의 0%였고, latency도 820ms로 느리긴 하나 충분히 사용 가능한 수준이었다. 그러나 Level 700부터 CPU 사용률 100%를 찍고 본격적인 병목이 시작되었다. 이정도가 Go의 한계라고 볼 수 있겠다.
이 지표는 단순한 CPU 사용량 비교를 넘어서, Go가 멀티스레드 + 멀티코어 + 병렬 처리를 효과적으로 수행해 내고 있다는 증거이기도 하다. Flask는 GIL 제약에 의해 1개의 스레드(코어)만 활용했기에 최대 사용률이 16%정도에서 머물렀으나, Go는 CPU 사용률 100%를 달성하며 CPU의 모든 자원을 활발히 활용하고 있다는 것을 증명했다.
"병목이 어디부터 시작되었는가?" 를 기준으로 Flask와 Go를 비교하면 아래와 같다.
Flask: Level 3 (연산 30만번)
Go: Level 700 (연산 7000만번)
...어이가 없을 정도의 차이다.
심지어 Go는 Level 1000일 때, 즉 연산 1억번이 필요한 요청이 초당 50개씩 들어왔을 때도 드랍률 30%, latency 4s 수준이었다. Flask와 비슷한 수준으로 망하려면 레벨을 어디까지 올려야 할 지 감이 안 잡힌다.
이번 실험을 통해, MSA 아키텍처의 구성 방법에 따라 성능이 얼마나 차이날 수 있는지를 다시 한 번 증명했다.
파이썬 워커를 코어 수 만큼 늘린다면, 모든 코어를 활용하니 Go와 비슷해지지 않을까?
...라는 생각을 했어서, 조금 공부해 보았다. 결과부터 말하면, "전혀 그렇지 않다". 물론 성능이 조금 나아지긴 하겠지만, Go와의 성능차이를 유의미하게 좁히지 못한다. 왜냐?
워커를 늘린다는 것은, 프로세스를 늘린다는 것이다. 파이썬의 GIL 제약은 프로세스 단위로 전파되기에, 워커 1개 당 1개의 코어를 활용할 수 있어 Go와 얼핏 비슷한 것 처럼 보인다. 그러나 이것은 자원 공유/문맥 전환 관점에서 매우 큰 차이가 있다.
첫번째 이유
하나의 Flask가 여러 개의 워커(프로세스)를 다룬다 하더라도, 결국 결과는 Flask에서 집계되어야 한다. 그러기 위해선 프로세스 간 통신 메커니즘(IPC)가 필요하고, 프로세스 간 문맥 전환(Context Swicting)이 필요하다. 문제는 이 두 작업 모두 상당히 큰 오버헤드를 초래한다는 것이다. 심지어 프로세스 자체도 메모리를 많이 차지한다.
두번째 이유
Go의 M:N 메커니즘과 Goroutine의 엄청난 효율성 때문이다. Go는 하나의 프로세스 내에서 멀티스레드로 동작하는데, 스레드 간 문맥 전환 비용을 최소화 시키기 위해 더 작은 작업 단위인 Goroutine에 작업을 부여한다. Goroutine은 스레드 생성/전환에 비해 오버헤드가 수십~수천 배 낮다. 이렇게 양산된 Goroutine들은 각 요청과 1:1로 매핑되며, 이 Goroutine들이 멀티스레드에 적절히 분배되어 매우 효율적인 병렬 처리를 가능하게 한다. 즉 스레드 생성/전환 비용을 Goroutine 생성/전환 비용으로 전환해 극한의 효율을 뿜어내는 것이다.
-> 따라서 파이썬이 워커를 늘리더라도, Go의 성능을 유의미하게 따라잡지 못 한다.
Flask와 Go의 CPU Bound, I/O Bound의 효율성 차이를 더 상세히 알아보고 싶다면 아래 글을 참고하라.
[msa-perf-lab] Python과 Go 비교: I/O & CPU Bound 작업에서의 동시성 차이 분석 - GIL, Gouroutine, M:N 스케줄링
MQ 비동기 도입 전/후 테스트를 진행하며, 파이썬의 I/O 작업 처리 방식에 궁금증이 생겼다. 1초가 걸리는 요청을 초당 100개씩 보냈는데도 1초마다 100개를 전부 응답했기 때문이다. 파이썬은 GIL 때
yskisking.shop
==========
msa-perf-lab 깃허브:
https://github.com/YangSunkue/msa-perf-lab
==========
프로젝트를 시작할 땐 이 정도로 깊게 파게 될 줄 몰랐다. 단순히 기술을 써보고, 성능을 테스트하는 수준에서 머무를 줄 알았다.
그러나 직접 실험 환경을 구축하고 테스트를 진행하는 동안 의문점들이 끝없이 쏟아졌다. "이건 왜 이렇게 동작하지?", "원리가 뭐지?", "이렇게 바꾸면 될 것 같은데?" 등등 말이다. 프로젝트를 진행하며 자연스럽게 다양한 트러블 슈팅을 하고 의문점들을 해결하며 기술에 대한 이해도와 깊이가 많이 증가하는 것 같다.
그러나 두려운 건, 깊이가 증가할 수록 더 깊은 곳을 보게 된다는 점이다. 파도 파도 끝이 없다. 계~속 공부해도 계~속 새로운 궁금증이 생길 것 같다. 그러나 그게 내가 개발을 좋아하는 이유니까, 동시에 개발하길 잘 했다는 생각도 든다.