[msa-perf-lab] 메시지 큐(RabbitMQ) 비동기 처리 전후 I/O 작업 성능 테스트
이번 성능 테스트에서는 I/O 바운드 작업에 대한 클라이언트 응답 시간을, 메시지 큐 비동기 처리 도입 전/후로 테스트 했다.
사용자 -> Flask -> Go(Gin) 흐름으로 사용자 요청이 전달되고, 실제 비즈니스 로직 작업은 항상 Go에서 한다. 이 때, 실제 비즈니스 로직이 아닌 time.sleep() 함수로 대체하여 병목 시간 1초를 시뮬레이션한다.
기존 방식인 동기(Sync)방식은, Flask에서 Go에게 직접 요청을 건네고 Go가 1초 후 응답하는 것을 기다렸다가 클라이언트에게 응답한다.
메시지 큐 비동기(Async)방식은, Flask에서 RabbitMQ에 메시지를 발행(publish)하고 클라이언트에게 즉시 응답한다. Go의 컨슈머는 무한 대기 상태로 있다가, 큐에 메시지가 publish되면 자동으로 감지해 해당 태스크를 처리한다.
즉 동기(Sync) 방식은 클라이언트 응답속도가 최소 1초 이상이 될 것이고,
메시지 큐 비동기(Async) 방식은 클라이언트 응답속도가 ms단위일 것이다. 큐에 넣고 즉시 응답하니까.
예상대로 동작할 지 실제로 테스트 해보자.
Flask 측 동기/비동기 서비스 함수

Flask Gateway에 요청이 오면, 위 둘 중 하나의 함수로 연결된다.
동기 함수는 Go서버가 1초 뒤에 응답하는 것을 기다렸다가 응답하는 함수고,
비동기 함수는 RabbitMQ에 메시지 발행 후 Go를 기다리지 않고 즉시 응답한다.
메시지 발행 함수 (RabbitMQ)

서비스에서 호출하는 publish_message 함수는 이렇게 구현되어 있다. 이 함수를 호출하면 자동으로 커넥션을 가져오고, 메시지를 publish 한다.
메시징 라이브러리는 Kombu를 활용했는데, 처음에 Pika를 사용하다가 Kombu로 바꿨다. 그 과정은 아래와 같다.
1. Pika 라이브러리 활용, Race Condition 문제 발생
Pika 라이브러리를 활용해 테스트를 진행하였더니 고부하 환경을 버티지 못해 Race Condition 문제가 발생했고, 스레드 간 커넥션/채널 경합이 일어나며 대부분의 요청이 실패하는(특히 고RPS 환경에서) 문제가 발생했다. 이는 Pika 라이브러리 자체가 내부적으로 Thread-safe하지 않기 때문이었다.
2. Pika 라이브러리 활용, Race Condition 문제 해결, 커넥션 생성 오버헤드 문제 발생
1번 방식은 하나의 커넥션을 공유해서 문제가 발생했기에, 모든 요청이 별개의 커넥션을 생성하여 활용하도록 했다. 결과적으로 Race Condition 문제는 완벽히 사라졌고 요청 성공률 100%를 달성했지만, 응답속도가 동기와 비슷한 수준으로 형편없었다. 이는 모든 요청이 별개의 커넥션을 생성/삭제 할 때 일어나는 오버헤드가 매우 크기 때문이었다.
3. Kombu 라이브러리 활용, Race Condition + 커넥션 생성 오버헤드 문제 해결 (모든 문제 해결)
Pika 라이브러리의 한계를 느껴, Kombu 라이브러리로 교체했다. Kombu는 내부적으로 커넥션 풀(Connection Pool)을 활용하고, Thread-safe한 특성을 가지기 때문에 Race Condition 문제에서 자유롭다. 따라서 고부하 환경에 적합한 라이브러리다. 교체 후 Race Condition 및 커넥션 생성 오버헤드 문제가 모두 해결되었고, 원하는 테스트 결과를 얻었다. (결과는 아래에)
Go 서버 메시지 처리 함수

Go서버는 stream 형태의 channel(consumer)을 활용해 무한히 대기하다가, 메시지가 발행되면 자동으로 이 함수를 실행한다.
I/O 작업을 실행한 후 Ack(처리 완료 메시지)를 남기는데, Ack는 큐에서 메시지를 삭제해도 된다는 일종의 알림이다.

1초 대기하는 시뮬레이션 함수이다. 동기/비동기 모두 I/O 작업은 이걸로 대체된다.
K6 트래픽 생성 스크립트

테스트 조건은 아래와 같다.
RPS(초당 요청 수): 50 ~ 400 (50씩 증가)
DURATION(지속시간): 30s
maxVU(최대 가상 사용자 수): 100
RPS 400일 경우, 30초동안 12000개의 요청이 가는 것이다.
RPS를 증가시키며 동기/비동기 테스트를 모두 진행한다.
50sync -> 50async -> 100sync -> 100async ...

테스트 시작!
테스트 결과 - 평균 응답시간(Avg Latency)

응답시간은 클라이언트가 요청을 보내고 응답을 받기까지의 시간을 의미한다. 왼쪽부터 RPS를 50씩 올려가며, 동기/비동기를 묶어 진행했다.
그래프를 보면 동기는 RPS에 관계없이 평균 1s,
비동기는 평균 2~4ms 정도의 응답시간을 보인다. 무려 500배 차이가 난다!!!
테스트 결과 - P(95) 응답시간 (P95 Latency)

P95는 전체 요청 중 95%가 해당 값 이하의 응답시간을 가졌다는 의미이다.
비동기 결과를 보면 2~5ms 정도로 평균값보다 약간 더 높고, 간간히 64ms 까지 튀어있다. 그러나 이 정도는 큰 문제가 없다고 볼 수 있다.
테스트 결과 - 처리량 (Throughput)

초당 처리량은 1초동안 몇 개의 요청에 성공 응답을 보냈느냐를 의미한다.
VU를 100으로 제한해 둔 결과, 동기는 RPS 100부터 처리량이 100 정도에서 정체된 반면,
비동기는 RPS크기에 따라 처리량이 계속해서 증가한다!
이는 비동기 방식이 K6에서 세팅해 둔 모든 요청을 안정적으로 받아 처리했다는 뜻이다. 현재 결과를 보니, RPS를 큰 폭으로 올려도 안정적일 것으로 예상된다.
그럴 수 밖에 없는 게, 동기 방식은 무조건 1초를 기다려야 응답이 오니 1초에 VU 한 명당 1개밖에 처리할 수 없는 것은 당연하다. 비동기 방식은 1초를 기다릴 필요가 없으니 같은 VU를 가지고도 훨씬 더 많은 요청을 처리할 수 있는 것이다.
테스트 결과 - 총 요청 대비 드랍률(Drop-rate)

결과를 보면, 동기 드랍률밖에 없다. 왜냐하면, 비동기는 단 한 개의 요청도 드랍하지 않았기 때문이다.
동기 방식은 100RPS 까지는 드랍률 2.97% 정도로 크게 문제가 없는 듯 보였으나,
150RPS 부터 갑자기 34%로 치솟더니,
400RPS 에서는 무려 총 요청 중 75%를 드랍했다. 즉, 예정된 12000개의 요청 중 3000개만 보냈고, 나머지 9000개는 이전 요청 응답을 기다리다가 보내지도 못하고 테스트가 종료된 것이다.
흠.. 근데 여기서 든 의문이 있다.
VU를 100으로 고정했으니, 당연히 초당 100개만 처리할 수 있는 것 아닌가? 내부 로직을 1초 걸리게 설계해 놓고, RPS는 올리면서 VU를 고정하면 당연히 드랍률이 올라가지.
그렇다면.. VU를 RPS 만큼 올리면 동기 방식도 드랍률이 떨어질 것 같은데?
뭐 그렇긴 하다. 그러나 그것은 테스트 목적과 어긋나며, 아키텍처 효율성이 아닌 "시스템 자체의 한계"를 측정하는 꼴이 되어 버린다. 우리가 테스트 해야 할 것은 같은 조건에서 동기/비동기 방식의 효율 차이이다.
VU 수는 서버 측 스레드 개수로 치환할 수 있다. 왜냐하면 VU 1개가 요청 1개를 보내고 1초 기다리는 동안, 해당 작업을 맡은 스레드도 1초 동안 Blocking 되기 때문이다. 즉, 요청 1개당 1개의 스레드가 묶인다. VU가 무한이라고 가정했을 때 RPS가 100이면 초당 100개의 스레드가 묶이고, RPS가 10000이면 초당 10000개의 스레드가 묶인다. "엄청난 비효율" 이다.
그러나 비동기 방식은 Input/Output 작업을 분리함으로서 훨씬 적은 수의 스레드로 수많은 요청을 처리할 수 있다. 위쪽에서 보았던 평균 응답속도 2ms를 대입하면, 동기 방식(1s)보다 500배 많은 요청을 처리할 수 있다는 뜻이 된다. 물론 코어 서버(Go)에서 실제로 처리하는 데에는 좀 더 많은 시간이 걸리겠지만, 애초에 즉시 처리하지 않아도 되는 로직에 메시지 큐를 적용하는 데다가 Go서버는 병렬/비동기 처리에 특화되어 있으니 그것은 큰 문제가 아니다.
정리 (RPS 400, VU 100, I/O 대기시간 1초 기준)
| 방식 | 평균 응답시간(Avg Latency) | 초당 처리량(Throughput) | 총 요청 대비 드랍률(Drop-rate) |
| 동기(Async) | 1s (1초) | 100 (RPS 100부터 정체) | 75% |
| 메시지 큐 비동기(Async) | 2~4ms(0.002~0.004초) | 400 (RPS 수만큼 증가) | 0% |
그야말로 엄청난 효율 차이를 보인다. 특히 클라이언트 측 응답 속도가 엄청나게 개선된다는 점이 가장 눈에 띄며, 실제 작업을 Core Engine(Go)에서 처리하니 Gateway 부담이 현저히 줄고, Core Engine은 수평적 확장이 용이하니 확장성 측면에서도 큰 장점을 갖게 된다.
이 정도면 메시지 큐 적용할 수 있는 모든 곳에 적용하고 싶다는 생각이 들 정도다.
==========
msa-perf-lab 깃허브:
https://github.com/YangSunkue/msa-perf-lab
==========
Go 서버 Task 처리 현황
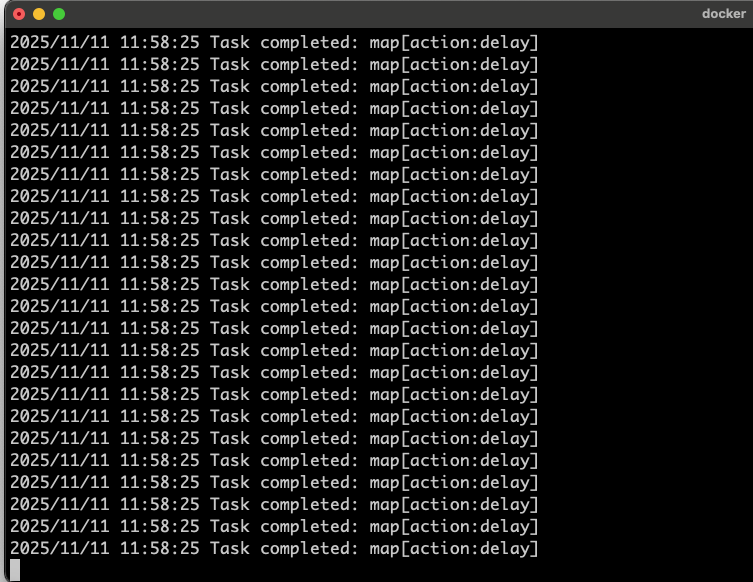
Go 서버 로그인데, 오류 하나 없이 완벽하게 처리했다.
시간을 보면 전부 같은 시간에 처리되어 있는데(11:58:25), Go 서버에서 메시지 큐 태스크를 비동기 + 병렬로 잘 처리하고 있다는 뜻이다.
Go는 채널의 데이터 공유가 아닌 "통신"특성 덕분에 비동기 문제에 대해 훨씬 안전하다. 따라서 개발자가 비동기 문제를 고민하지 않아도 안전하게 동시성 작업을 할 수 있게 해 준다. 그야말로 혁명이다.
이번 테스트에선 동기vs비동기 성능 차이만 측정했지만, 다음엔 Go 서버에서 태스크 처리 실패 시 제어 흐름을 구현해 보려고 한다. DLQ(Dead Letter Queue)를 도입해서 말이다.